Smart Audio Asset Library
Capstone Project
This project is for Capstone Project of Haozhe Li @ University of Illinois.
- Presentation Slides: Google Slides
- Github: GitHub
Introduction
Welcome to Smart Audio Asset Library, a state-of-the-art semantic search engine designed for the modern audio professional. By leveraging Contrastive Language-Audio Pretraining (CLAP), LLM-enriched metadata, and hybrid retrieval strategies, this project transforms a collection of raw audio files into a searchable, organized, and intelligent library.
Traditional audio search relies on filenames or manual tagging—a process that is time-consuming and often misses the "vibe" or specific content of a sound. Audio AI Search bridges this gap, allowing you to find a "dark, cinematic synth pad" or "energetic city background noise" as easily as searching for a text document.
🚀 Quick Start
Prerequisites
- Python 3.10+
- Node.js 18+
- Qdrant (Cloud or Local)
- OpenAI API Key (for dense text embeddings and LLM filtering)
- Google Gemini API Key (for automated audio annotation)
- Cloudflare R2 (for asset storage)
Installation
-
Clone the repository:
git clone https://github.com/Haozhe-Li/audio-ai-search.git cd audio-ai-search -
Backend Setup:
cd backend python -m venv venv source venv/bin/activate # macOS/Linux pip install -r requirements.txt # Pre-download CLAP model weights python scripts/prewarm_clap.py -
Frontend Setup:
cd ../frontend npm install -
Environment Configuration: Create a
.envfile in thebackenddirectory with your API keys:OPENAI_API_KEY=your_key GEMINI_API_KEY=your_key QDRANT_URL=your_url QDRANT_API_KEY=your_key R2_ACCOUNT_ID=your_id R2_ACCESS_KEY_ID=your_key R2_SECRET_ACCESS_KEY=your_key -
Run the Application:
# Terminal 1: Backend cd backend uvicorn main:app --reload # Terminal 2: Frontend cd frontend npm run dev
🧠 Motivation
The "needle in a haystack" problem is real in audio production. Libraries often grow to thousands of files with names like REC_001.wav or Synth_04_rev2.mp3.
Existing solutions often fall into two categories:
- Keyword-based: Fast but limited. If a file isn't tagged "rain," you won't find it when searching for "stormy weather."
- Manual Tagging: Accurate but unscalable.
Audio AI Search proposes a third way: Multi-Modal Semantic Retrieval. By mapping both audio and text into a shared latent space, we can compute similarity between a natural language query and the actual acoustic features of a sound.
✨ Key Features
🔍 Hybrid Semantic Retrieval
We don't just use one vector. We use three:
- Dense Audio Vector (CLAP): Captures the acoustic "soul" of the audio.
- Dense Text Vector (OpenAI): Captures the semantic meaning of the AI-generated descriptions.
- Sparse Text Vector (BM25): Ensures exact keyword matches (e.g., "TR-808") aren't lost in the "fuzziness" of dense embeddings.
🤖 LLM-Enriched Querying
Using LangChain and GPT-5, our system "understands" your intent. If you search for "bright sounds faster than 120bpm," the LLM agent extracts:
spectral_centroid_mean > 2000bpm > 120These are applied as hard filters in Qdrant, while the remaining query is used for semantic similarity.
📝 Gemini-Powered Annotation
Every uploaded file is automatically "listened to" by Google Gemini. It generates:
- A detailed technical description.
- A caption for any human speech found.
- High-level categories (Music, SFX, Speech).
📂 Smart Collections
Tired of organizing folders? The Smart Collect feature uses Gemini's classifications to automatically move your files into a logical directory structure (/Music, /Sound Effects, etc.) with one click.
🏗 Architecture
The system follows a modern RAG (Retrieval-Augmented Generation) architecture tailored for audio assets.
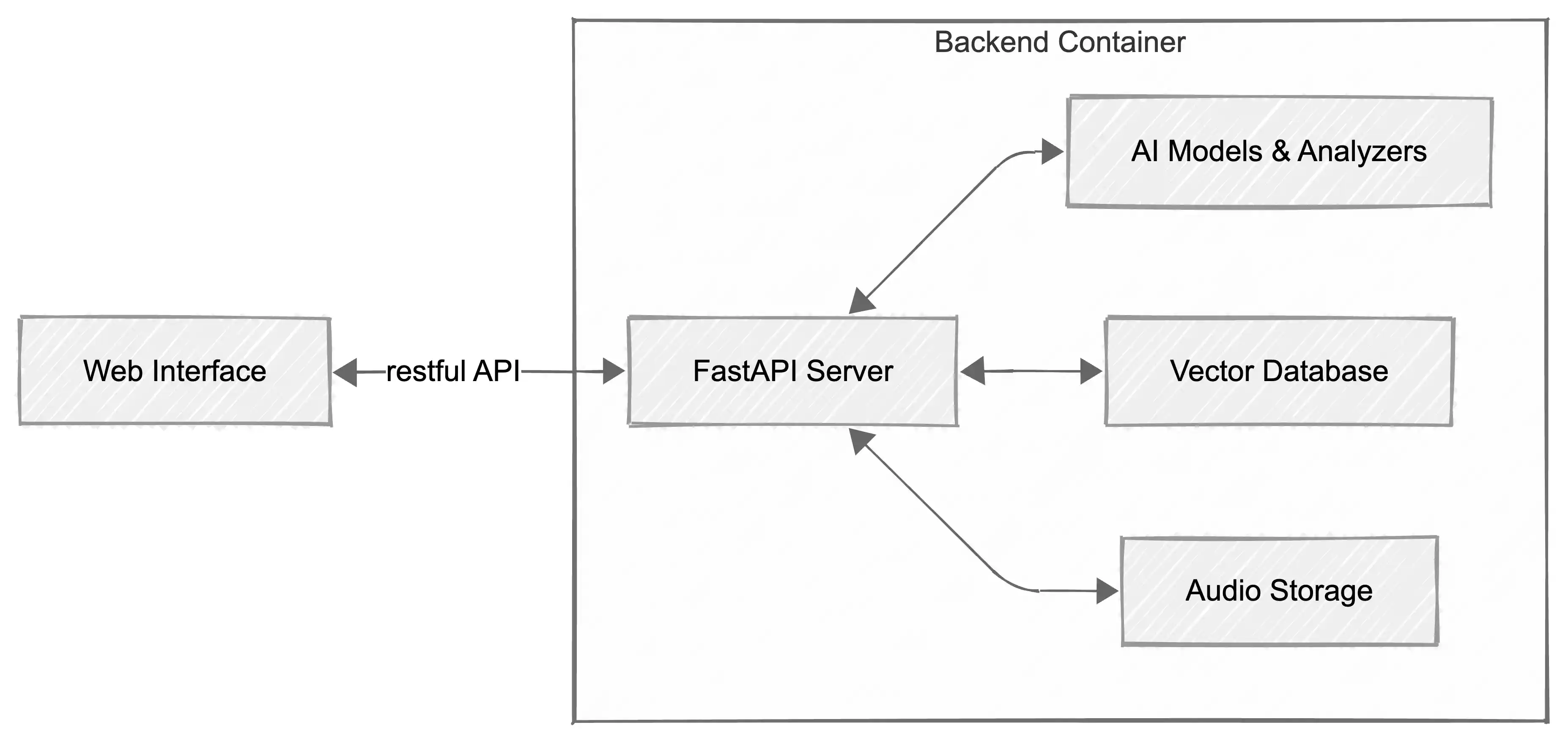
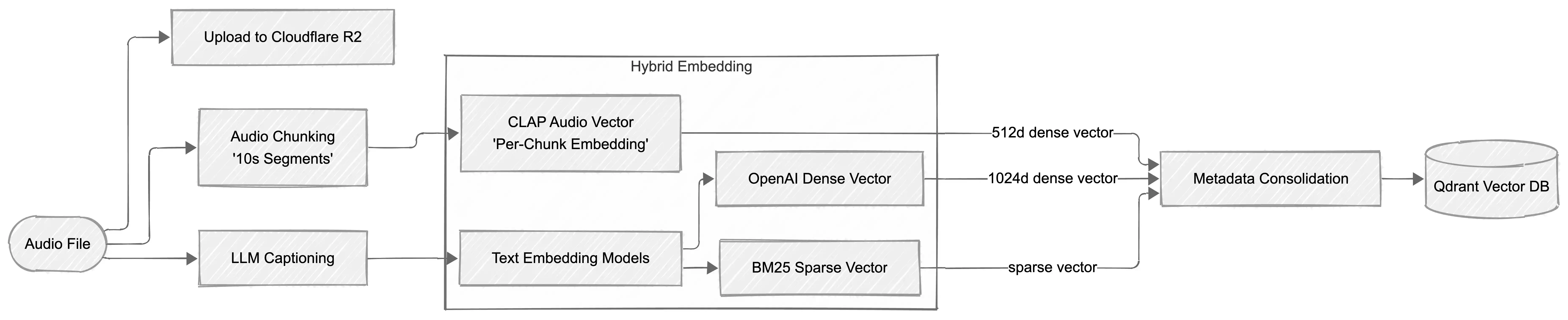
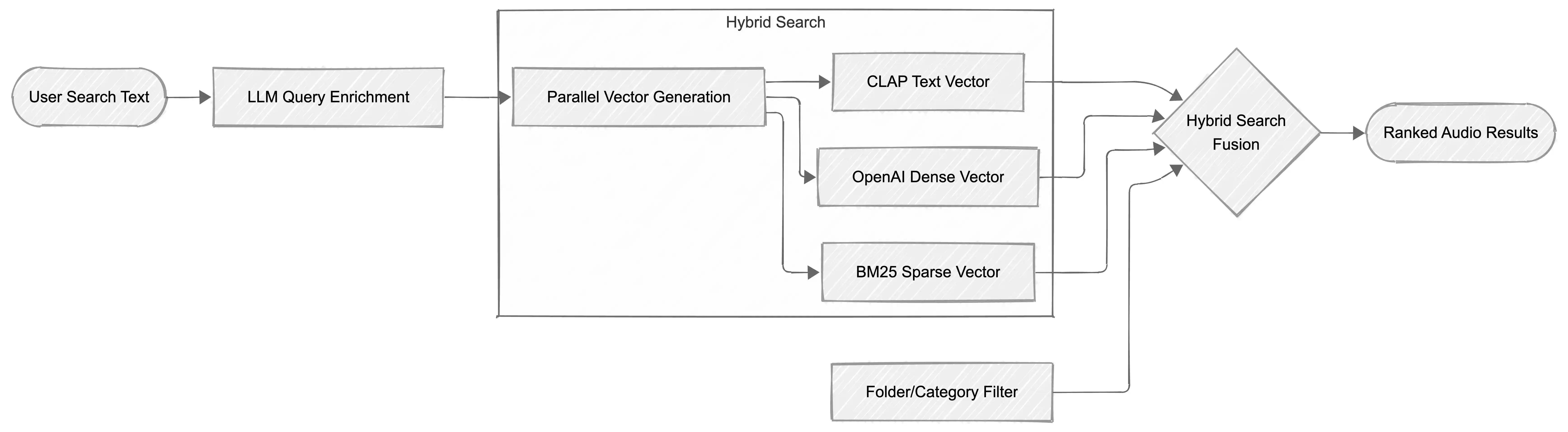
Retrieval Logic: RRF & Max-Sim
- Reciprocal Rank Fusion (RRF): Combines the rankings from our three vector sources to provide a unified, robust result set.
- Max-Sim Aggregation: Since audio is indexed in chunks, we use a "Maximum Similarity" strategy to ensure each audio file appears only once in the search results, represented by its most relevant segment.
📊 Evaluation
We benchmarked our system using a rigorous evaluation suite across four distinct scenarios. The results demonstrate the significant impact of Hybrid RAG and Chunked Indexing, particularly in complex audio environments.
Real-World Performance Metrics
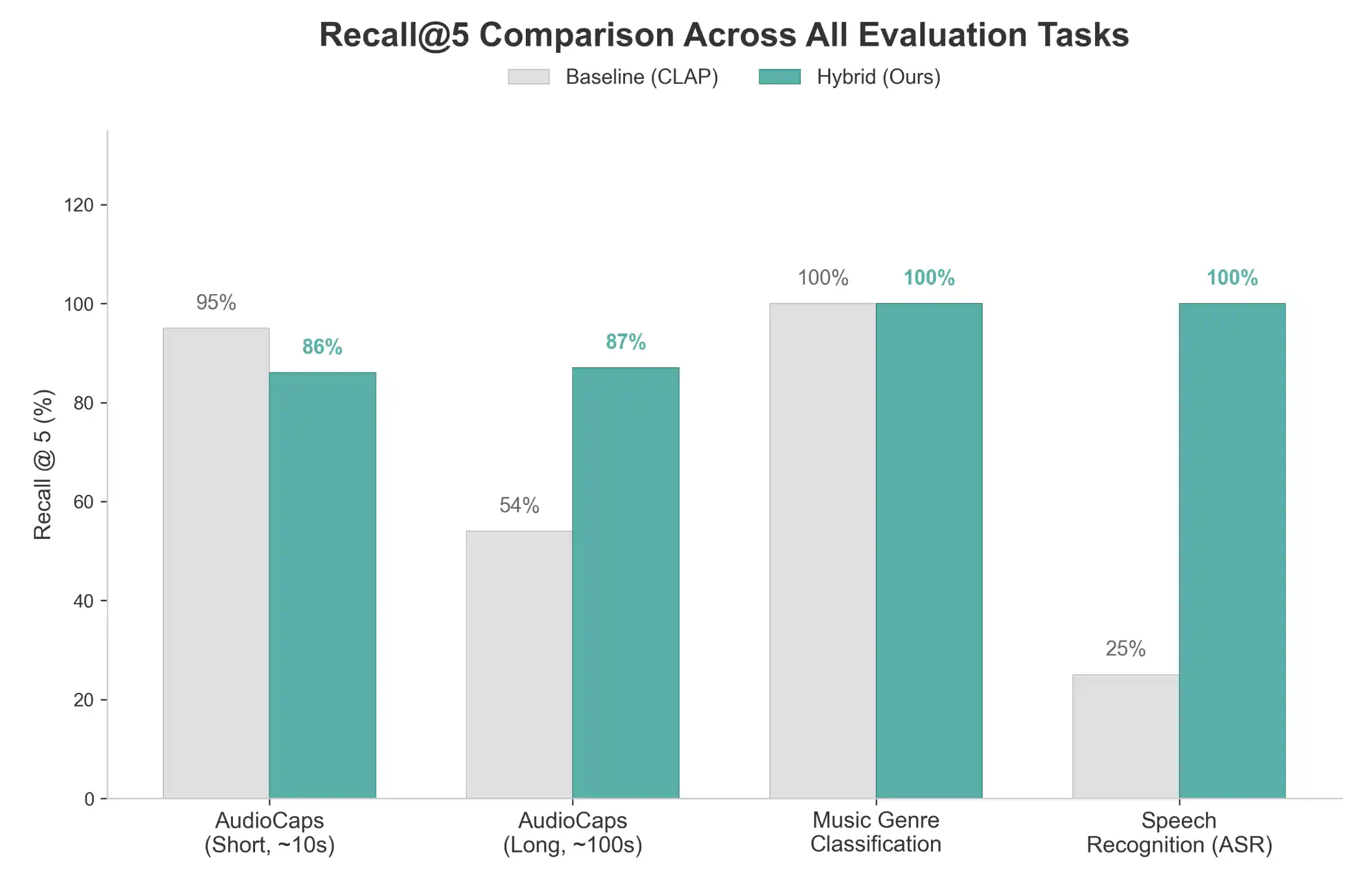
| Scenario | Metric | Baseline (Global CLAP) | Hybrid RAG (Chunked) | Improvement | | :--- | :--- | :--- | :--- | :--- | | ASR (Speech) | Recall@5 | 25.0% | 100.0% | +300% | | Long Audio | Recall@5 | 54.0% | 87.0% | +61% | | Music Genre | Recall@5 | 100.0% | 100.0% | - | | Short Audio | Recall@5 | 95.0% | 86.0% | -9% |
Analysis
- Speech & ASR Mastery: The most dramatic improvement is seen in Speech retrieval. While CLAP often struggles with specific semantic content in speech, our Hybrid RAG (integrating Gemini-extracted transcriptions) achieves a perfect 100% Recall@5, compared to just 25% for the baseline.
- Long Audio Retrieval: For long recordings, global embeddings "smear" the content. Our chunked approach with RRF fusion allows for precise retrieval of specific segments, improving Recall@5 from 54% to 87%.
- Semantic Consistency: In simple short audio scenarios (AudioCaps), the baseline global embedding remains highly effective. The slight dip in hybrid performance here suggests that for very short, single-subject clips, the "pure" audio signal is often sufficient.
🛠 Future Work
- Multi-Modal Input: Search for audio using an image (e.g., upload a photo of a forest to find forest soundscapes).
- Domain Fine-Tuning: Fine-tuning CLAP on specialized foley and sound design datasets.
- Temporal Search: Improved UI for navigating specifically where in a 2-hour recording a sound occurred.
- Offline Mode: Local vector storage and embedding generation for privacy-conscious users.
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
Built with ❤️ by Haozhe Li